flowchart TD
d[ds_args]-->ld["load_data()"]-->dls[DataLoaders<br>dls]-->L[Learner]
D[(Data)]-->ld
m[model_args]-->M[Model<br>VAEWaveNet]-->L
Lo[Loss<br>Gaussian mixture+BetaKLD]-->L
O[Optimizer<br>Adam]-->L
C[Callbacks<br>& Metrics]-->L
L-->lr["learn.lr_find()"]-->T["Training<br>learn.fit_one_cycle(Epochs, lr_max)"]
Model training on FBM
Example of training SPIVAE to extract the relevant physical parameters of fractional Brownian motion.
In this tutorial, we aim at training SPIVAE with the dataset of fractional Brownian motion (FBM) to extract the generalized diffusion coefficient \(D\), and the anomalous exponent \(\alpha\).
To train the models, we use the fastai library that provides easy to use methods. First, we gather everything needed to train (the data, the model, the loss, the optimizer, the callbacks, and metrics) into a Learner object. We will use the Learner to hold all the parameters and handle the training procedure.
Setup
We start selecting the parameters of the device to train on, the dataset, and the model.
DEVICE= 'cpu' # 'cuda'
print(DEVICE)cpuData
To construct the dataset of FBM, we vary \(D\) logarithmically inside the range \(10^{-5}\) and \(10^{-2}\) such that the displacements are smaller than one. At the same time, we choose \(\alpha\in[0.2, 1.8]\). We take the same amount of trajectories for each combination of parameters, about 100 thousand trajectories in total. We split them in training and validation sets, and select a batch size bs.
Ds = np.geomspace(1e-5,1e-2, 10)
alphas = np.linspace(0.2,1.8,21)
n_alphas, n_Ds = len(alphas), len(Ds)
ds_args = dict(path="../../data/raw/", model='fbm', # 'sbm'
N=2, # small dataset for testing
# N=int(100_000/n_alphas/n_Ds),
T=400,
D=Ds, alpha=alphas,
N_save=100, # small dataset for testing
# N_save=6_000,
T_save=400,
seed=0, valid_pct=0.2, bs=2**8,)ds_args.update(dict(N=N=int(100_000/n_alphas/n_Ds), N_save=6_000))We generate training data as explained in the data docs. You can skip this step if you already generated data using the data generation notebook.
dataset = AD.create_dataset(T=ds_args["T"], N_models=ds_args["N"],
exponents=ds_args["alpha"],
dimension=1, models=[2], # fbm
T_save=ds_args["T_save"], N_save=ds_args["N_save"],
save_trajectories=True, path="../../data/raw/")We create the data loaders dls for training and validation with the parameters we selected above.
dls = load_data(ds_args).to(DEVICE)
dls[1].drop_last = True # for validation to throw the last incomplete batch or not
dls[0].drop_last, dls[1].drop_last, dls[1].bs, dls.device(True, True, 256, 'cpu')Model
We set a small model to train rapidly, but large enough to provide adequate expressiveness. We fix 6 latent neurons, as a priori, we do not know how many neurons will encode the trajectory parameters.
model_args = dict(# VAE #################
o_dim=ds_args['T']-1,
nc_in=1, # 1D
nc_out=6, # = z_dim
nf=[16]*4,
avg_size=16,
encoder=[200,100],
z_dim=6, # latent dimension
decoder=[100,200],
beta=0,
# WaveNet ############
in_channels=1,
res_channels=16,skip_channels=16,
c_channels=6, # = nc_out
g_channels=0,
res_kernel_size=3,
layer_size=4, # 6 # Largest dilation is 2**layer_size
stack_size=1,
out_distribution= "Normal",
num_mixtures=1,
use_pad=False,
model_name = 'SPIVAE',
)We instantiate a model and check the forward pass works for a random batch.
model = VAEWaveNet(**model_args).to(DEVICE)
print('RF:', model.receptive_field, 'bs:', dls.bs)
x,y=b = dls.one_batch(); t = model(x)Loss
We define the loss function as defined in Utils. The initial loss for this dataset is around 1.5, bigger than that the initialization provides an unstable model that may not train properly.
loss_fn = Loss(model.receptive_field, model.c_channels,
beta=model_args['beta'], reduction='mean')
l = loss_fn(t,y).item();
print('Initial loss: ',l)
assert l<1.5, 'Initial loss should be around 1.5 or less'RF: 32 bs: 256
Initial loss: 0.9456117153167725Callbacks
We now set a few callback functions to show relevant information during training. The first two update a plot of the total loss for training and validation, and the Kullback-Leibler divergence (\(D_{KL}\)) of the latent neurons, respectively. The other two record the reconstruction loss and the \(D_{KL}\) of each latent neuron.
callbacks = [ShowLossCallback(), ShowKLDsCallback(),
GMsCallback(model.receptive_field,model.c_channels),
KLDsCallback(model.c_channels)]Metrics
We add two metrics to follow the reconstruction loss and the divergence term in a table at each epoch of the training.
metrics = [GaussianMixtureMetric(model.receptive_field, model.c_channels,reduction='mean'),
KLDMetric(model.c_channels,),
]Learner
With all the ingredients, we create the Learner with the default optimizer, Adam.
learn = Learner(dls, model, loss_func=loss_fn, opt_func=Adam, cbs=callbacks, metrics=metrics,)
if torch.cuda.is_available() and DEVICE=='cuda': learn.model.cuda()The learner can show us a summary including the model sizes and number of parameters.
learn.summary()VAEWaveNet (Input shape: 256 x 1 x 399)
============================================================================
Layer (type) Output Shape Param # Trainable
============================================================================
256 x 16 x 397
Conv1d 64 True
ReLU
____________________________________________________________________________
256 x 16 x 395
Conv1d 784 True
ReLU
____________________________________________________________________________
256 x 16 x 393
Conv1d 784 True
ReLU
____________________________________________________________________________
256 x 16 x 391
Conv1d 784 True
ReLU
____________________________________________________________________________
256 x 16 x 16
AdaptiveAvgPool1d
AdaptiveMaxPool1d
____________________________________________________________________________
256 x 512
View
____________________________________________________________________________
256 x 200
Linear 102600 True
ReLU
____________________________________________________________________________
256 x 100
Linear 20100 True
ReLU
____________________________________________________________________________
256 x 12
Linear 1212 True
____________________________________________________________________________
256 x 100
Linear 700 True
ReLU
____________________________________________________________________________
256 x 200
Linear 20200 True
ReLU
____________________________________________________________________________
256 x 512
Linear 102912 True
ReLU
____________________________________________________________________________
256 x 16 x 32
View
____________________________________________________________________________
256 x 16 x 393
ConvTranspose1d 784 True
ReLU
____________________________________________________________________________
256 x 16 x 395
ConvTranspose1d 784 True
ReLU
____________________________________________________________________________
256 x 16 x 397
ConvTranspose1d 784 True
ReLU
____________________________________________________________________________
256 x 6 x 399
ConvTranspose1d 294 True
ReLU
____________________________________________________________________________
256 x 16 x 399
Conv1d 32 True
____________________________________________________________________________
256 x 16 x 397
Conv1d 528 True
____________________________________________________________________________
256 x 32 x 395
Conv1d 1568 True
____________________________________________________________________________
256 x 32 x 399
Conv1d 192 True
Conv1d 272 True
Conv1d 272 True
____________________________________________________________________________
256 x 32 x 391
Conv1d 1568 True
____________________________________________________________________________
256 x 32 x 399
Conv1d 192 True
Conv1d 272 True
Conv1d 272 True
____________________________________________________________________________
256 x 32 x 383
Conv1d 1568 True
____________________________________________________________________________
256 x 32 x 399
Conv1d 192 True
Conv1d 272 True
Conv1d 272 True
____________________________________________________________________________
256 x 32 x 367
Conv1d 1568 True
____________________________________________________________________________
256 x 32 x 399
Conv1d 192 True
Conv1d 272 True
Conv1d 272 True
ReLU
Conv1d 272 True
ReLU
____________________________________________________________________________
256 x 3 x 367
Conv1d 51 True
____________________________________________________________________________
Total params: 262,885
Total trainable params: 262,885
Total non-trainable params: 0
Optimizer used: <function Adam>
Loss function: <SPIVAE.utils.Loss object>
Callbacks:
- TrainEvalCallback
- CastToTensor
- Recorder
- ProgressCallback
- ShowLossCallback
- ShowKLDsCallback
- GMsCallback
- KLDsCallbackLearning rate finder
Finally, we need a learning rate. Conveniently, fastai includes a learning rate finder. This finder can suggest some points, each based on a criterion that guides us. Hence, we try with one order above and below the default criterion, the valley.
learn.lr_find()SuggestedLRs(valley=9.120108734350652e-05)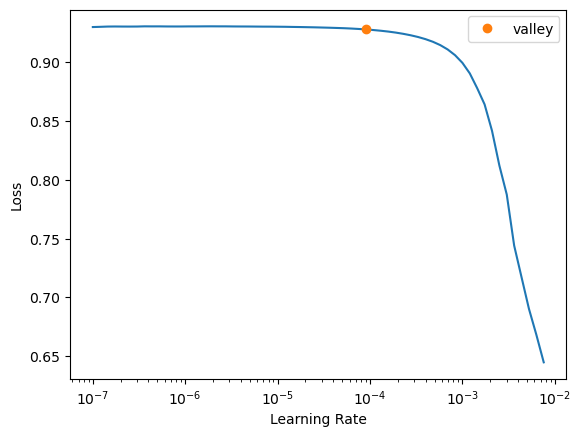
The valley is around \(10^{-4}\), thus we will start trying a learning rate of \(10^{-3}\) to see if we can learn fast.
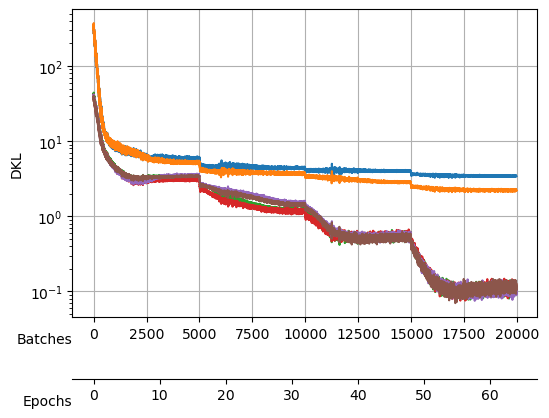
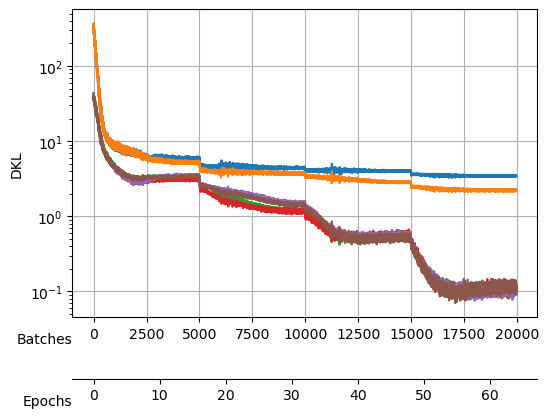
During the search, not only the loss was logged but also the \(D_{KL}\) (thanks to the callback), which we can see here:
plt.semilogy(np.stack(learn.kl_ds.preds)); learn.kl_ds.preds=[]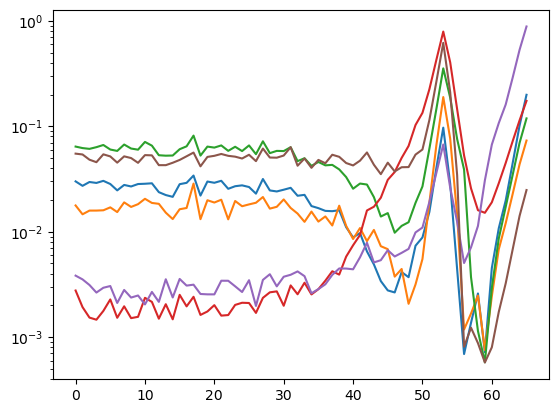
During the training, we will keep an eye on both the total loss and the \(D_{KL}\).
Training with \(\beta\)=0
We start training with \(\beta=0\) to have no additional constraint in the latent neurons and allow the VAE to use the full capacity of its bottleneck.
learn.loss_func.beta=0To ease the training, we update the model’s parameters following the learning rate schedule developed by Leslie N. Smith et al. (2017) and already implemented in fastai. We choose as the maximum learning rate the one derived from the finder above.
E=64learn.fit_one_cycle(E, lr_max=1e-3,)| epoch | train_loss | valid_loss | mix_gaussian_loss | kld | time |
|---|---|---|---|---|---|
| 0 | -1.315952 | -1.661407 | -1.661407 | 19.406342 | 01:09 |
| 1 | -2.112537 | -2.151353 | -2.151353 | 64.277298 | 01:10 |
| 2 | -2.239122 | -2.249071 | -2.249071 | 86.196838 | 01:11 |
| 3 | -2.244182 | -2.256283 | -2.256283 | 78.044266 | 01:10 |
| 4 | -2.238847 | -2.265728 | -2.265728 | 79.355087 | 01:10 |
| 5 | -2.185477 | -2.220979 | -2.220979 | 73.193192 | 01:11 |
| 6 | -2.157342 | -2.245884 | -2.245884 | 68.523232 | 01:11 |
| 7 | -2.011828 | -2.076498 | -2.076498 | 48.271271 | 01:10 |
| 8 | -2.026002 | -2.205460 | -2.205460 | 14.866062 | 01:10 |
| 9 | -2.146519 | -2.218804 | -2.218804 | 27.197741 | 01:12 |
| 10 | -2.164488 | -2.268744 | -2.268744 | 53.392033 | 01:11 |
| 11 | -2.094013 | -2.184355 | -2.184355 | 72.369965 | 01:10 |
| 12 | -2.228285 | -2.122396 | -2.122396 | 162.265594 | 01:10 |
| 13 | -2.266493 | -2.289713 | -2.289713 | 189.916687 | 01:10 |
| 14 | -2.229059 | -1.878625 | -1.878625 | 314.366608 | 01:11 |
| 15 | -2.244426 | -2.255815 | -2.255815 | 336.166351 | 01:10 |
| 16 | -2.272467 | -2.274356 | -2.274356 | 377.487793 | 01:11 |
| 17 | -2.277053 | -2.275987 | -2.275987 | 417.207703 | 01:10 |
| 18 | -2.269186 | -2.246015 | -2.246015 | 479.375000 | 01:11 |
| 19 | -2.293643 | -2.303562 | -2.303562 | 493.494781 | 01:10 |
| 20 | -2.299952 | -2.314991 | -2.314991 | 547.708008 | 01:10 |
| 21 | -2.322182 | -2.281061 | -2.281061 | 568.945740 | 01:10 |
| 22 | -2.310960 | -2.320824 | -2.320824 | 608.434265 | 01:10 |
| 23 | -2.315642 | -2.324992 | -2.324992 | 607.956360 | 01:11 |
| 24 | -2.332518 | -2.312339 | -2.312339 | 635.526489 | 01:11 |
| 25 | -2.317588 | -2.331322 | -2.331322 | 659.979919 | 01:10 |
| 26 | -2.326688 | -2.328422 | -2.328422 | 651.702820 | 01:11 |
| 27 | -2.339881 | -2.334195 | -2.334195 | 681.555664 | 01:11 |
| 28 | -2.329673 | -2.333597 | -2.333597 | 717.498901 | 01:10 |
| 29 | -2.340475 | -2.333066 | -2.333066 | 720.397827 | 01:10 |
| 30 | -2.338010 | -2.337913 | -2.337913 | 755.900269 | 01:11 |
| 31 | -2.332206 | -2.332510 | -2.332510 | 756.721130 | 01:12 |
| 32 | -2.351339 | -2.338526 | -2.338526 | 782.172852 | 01:11 |
| 33 | -2.340485 | -2.338783 | -2.338783 | 805.748047 | 01:11 |
| 34 | -2.340624 | -2.342476 | -2.342476 | 810.832153 | 01:13 |
| 35 | -2.343892 | -2.342334 | -2.342334 | 830.463257 | 01:11 |
| 36 | -2.348852 | -2.345546 | -2.345546 | 821.223083 | 01:11 |
| 37 | -2.355019 | -2.345020 | -2.345020 | 839.597351 | 01:11 |
| 38 | -2.345042 | -2.346593 | -2.346593 | 839.534668 | 01:11 |
| 39 | -2.355663 | -2.346778 | -2.346778 | 839.826233 | 01:12 |
| 40 | -2.342772 | -2.347796 | -2.347796 | 840.443481 | 01:11 |
| 41 | -2.358884 | -2.348896 | -2.348896 | 830.699219 | 01:11 |
| 42 | -2.349423 | -2.349129 | -2.349129 | 840.666992 | 01:11 |
| 43 | -2.348464 | -2.346027 | -2.346027 | 832.678467 | 01:12 |
| 44 | -2.352715 | -2.349886 | -2.349886 | 834.427307 | 01:11 |
| 45 | -2.344991 | -2.349920 | -2.349920 | 826.926025 | 01:11 |
| 46 | -2.341416 | -2.350274 | -2.350274 | 831.225464 | 01:11 |
| 47 | -2.350832 | -2.350190 | -2.350190 | 828.069336 | 01:12 |
| 48 | -2.345083 | -2.350618 | -2.350618 | 826.633118 | 01:12 |
| 49 | -2.360827 | -2.350861 | -2.350861 | 821.838623 | 01:11 |
| 50 | -2.352463 | -2.350962 | -2.350962 | 830.453674 | 01:12 |
| 51 | -2.347570 | -2.351095 | -2.351095 | 823.741089 | 01:12 |
| 52 | -2.360364 | -2.351196 | -2.351196 | 821.325806 | 01:12 |
| 53 | -2.343230 | -2.351074 | -2.351074 | 823.521729 | 01:11 |
| 54 | -2.355769 | -2.351494 | -2.351494 | 821.793335 | 01:12 |
| 55 | -2.358197 | -2.351494 | -2.351494 | 817.322815 | 01:12 |
| 56 | -2.359900 | -2.351530 | -2.351530 | 815.922485 | 01:12 |
| 57 | -2.349110 | -2.351698 | -2.351698 | 814.793518 | 01:11 |
| 58 | -2.355841 | -2.351716 | -2.351716 | 815.463562 | 01:11 |
| 59 | -2.358056 | -2.351770 | -2.351770 | 813.260559 | 01:15 |
| 60 | -2.354583 | -2.351813 | -2.351813 | 811.844543 | 01:12 |
| 61 | -2.344743 | -2.351826 | -2.351826 | 812.462219 | 01:13 |
| 62 | -2.350585 | -2.351825 | -2.351825 | 812.875671 | 01:12 |
| 63 | -2.355194 | -2.351831 | -2.351831 | 812.403564 | 01:12 |
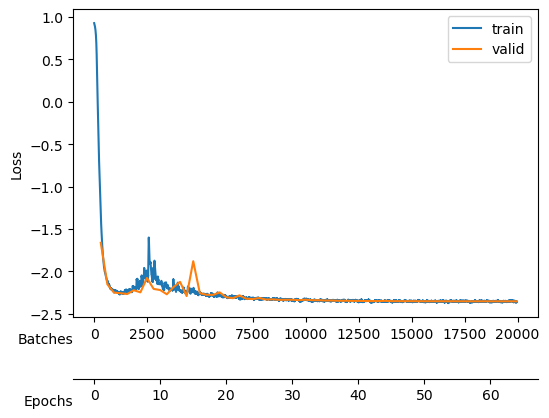
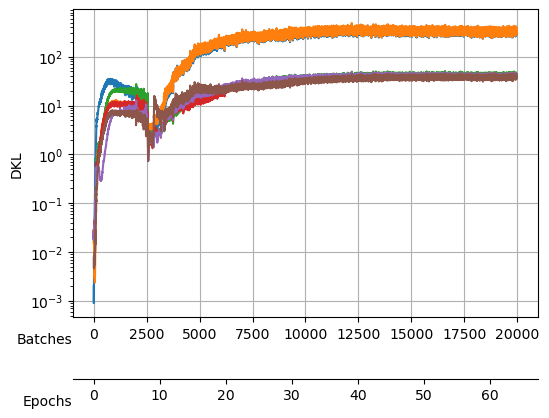
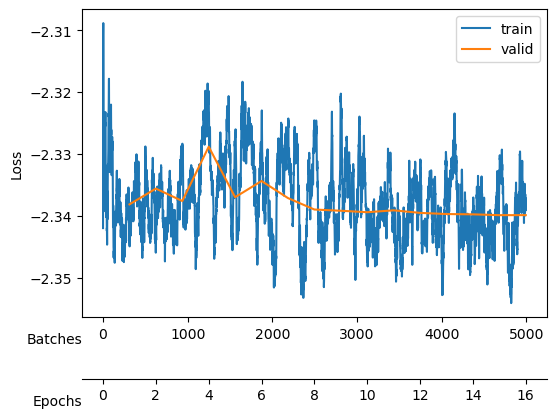
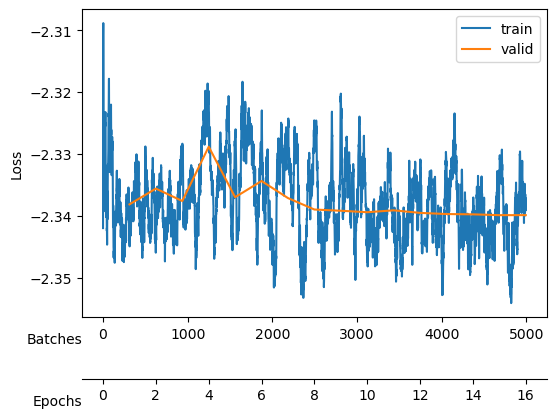
After training, we see a validation loss around -2.35 and two neurons that contribute the most to the \(D_{KL}\). We take a checkpoint of the model at this moment.
model_name = 'fbm' + f'_E{E}'
if not os.path.exists("./models/"+model_name+'.tar'):
save_model("./models/"+model_name, model, model_args, ds_args)Saved at ./models/fbm_E64.tarplt.semilogy(np.stack(learn.kl_ds.preds));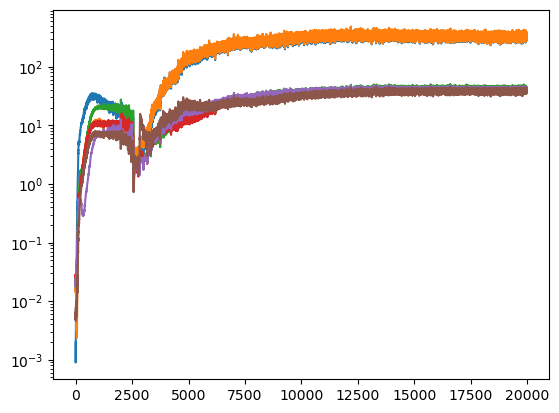
# se the actual learning rates and momentums set during this training cycle
lrs,moms = learn.recorder.hps['lr'],learn.recorder.hps['mom']
plt.plot(lrs);plt.plot(moms);Annealing \(\beta\)
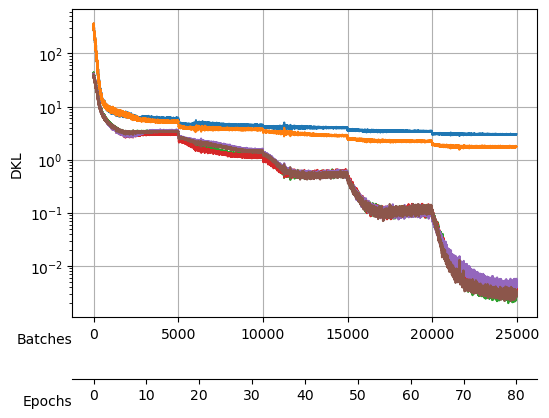
Now, we increase \(\beta\) to impose a Gaussian prior into the latent neurons distribution which effectively forces the encoding of the already present information to use the minimal number of neurons while noising out the rest of neurons.
E=64model_name = 'fbm' + f'_E{E}'
c_point, model = load_checkpoint("./models/"+model_name,device=DEVICE)learn.loss_func.beta=1e-4; model_args.update(dict(beta=1e-4))E=16learn.fit_one_cycle(E, lr_max=1e-3,)| epoch | train_loss | valid_loss | mix_gaussian_loss | kld | time |
|---|---|---|---|---|---|
| 0 | -2.324830 | -2.338405 | -2.349152 | 107.466675 | 01:09 |
| 1 | -2.338842 | -2.340303 | -2.345047 | 47.436031 | 01:10 |
| 2 | -2.339993 | -2.337490 | -2.341151 | 36.604542 | 01:10 |
| 3 | -2.337698 | -2.346305 | -2.349505 | 32.004436 | 01:10 |
| 4 | -2.342737 | -2.319283 | -2.322044 | 27.611586 | 01:10 |
| 5 | -2.343880 | -2.324024 | -2.326623 | 25.985027 | 01:10 |
| 6 | -2.344337 | -2.348159 | -2.350667 | 25.081089 | 01:10 |
| 7 | -2.343842 | -2.349709 | -2.352086 | 23.770494 | 01:11 |
| 8 | -2.345186 | -2.352701 | -2.355143 | 24.418821 | 01:10 |
| 9 | -2.355095 | -2.356360 | -2.358828 | 24.684273 | 01:09 |
| 10 | -2.358190 | -2.361038 | -2.363501 | 24.632402 | 01:11 |
| 11 | -2.362531 | -2.362979 | -2.365445 | 24.661421 | 01:11 |
| 12 | -2.357859 | -2.363399 | -2.365850 | 24.508953 | 01:10 |
| 13 | -2.358759 | -2.363714 | -2.366147 | 24.336988 | 01:10 |
| 14 | -2.360825 | -2.363775 | -2.366217 | 24.420610 | 01:10 |
| 15 | -2.355404 | -2.363865 | -2.366307 | 24.411386 | 01:10 |
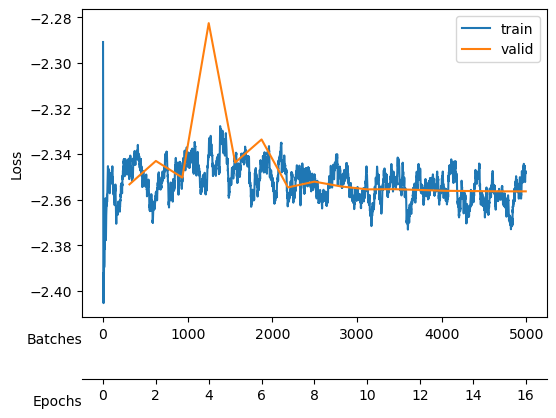
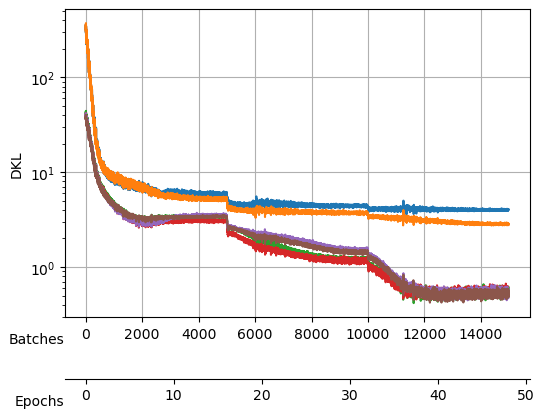
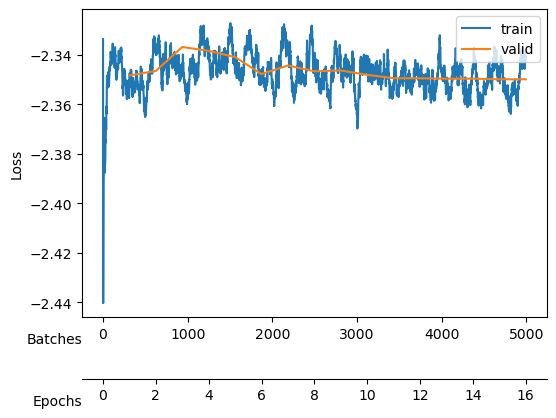
We save the model after each cycle, just in case all the neurons collapse due to a big \(\beta\).
E=64+16; model_name = 'fbm' + f'_E{E}'
if not os.path.exists("./models/"+model_name+'.tar'):
save_model("./models/"+model_name, model, model_args, ds_args)Saved at ./models/fbm_E80.tarThen, we increase the \(\beta\) and train again.
learn.loss_func.beta=6e-4; model_args.update(dict(beta=6e-4))learn.fit_one_cycle(16, lr_max=1e-3,)| epoch | train_loss | valid_loss | mix_gaussian_loss | kld | time |
|---|---|---|---|---|---|
| 0 | -2.353231 | -2.353524 | -2.364641 | 18.528250 | 01:09 |
| 1 | -2.348532 | -2.352497 | -2.362990 | 17.487579 | 01:10 |
| 2 | -2.342875 | -2.334392 | -2.344330 | 16.562178 | 01:11 |
| 3 | -2.346903 | -2.336486 | -2.345794 | 15.511265 | 01:10 |
| 4 | -2.330870 | -2.346205 | -2.356031 | 16.375021 | 01:10 |
| 5 | -2.349575 | -2.353170 | -2.362580 | 15.683105 | 01:10 |
| 6 | -2.347398 | -2.351249 | -2.360387 | 15.228333 | 01:11 |
| 7 | -2.345601 | -2.350861 | -2.359752 | 14.819258 | 01:10 |
| 8 | -2.352276 | -2.356376 | -2.364991 | 14.358064 | 01:10 |
| 9 | -2.356200 | -2.355854 | -2.364318 | 14.105173 | 01:10 |
| 10 | -2.350616 | -2.355227 | -2.363599 | 13.954180 | 01:12 |
| 11 | -2.355976 | -2.357581 | -2.365860 | 13.798420 | 01:10 |
| 12 | -2.354166 | -2.357984 | -2.366087 | 13.504392 | 01:10 |
| 13 | -2.359440 | -2.358157 | -2.366241 | 13.472176 | 01:10 |
| 14 | -2.343340 | -2.358246 | -2.366287 | 13.400112 | 01:10 |
| 15 | -2.365923 | -2.358313 | -2.366364 | 13.418869 | 01:10 |
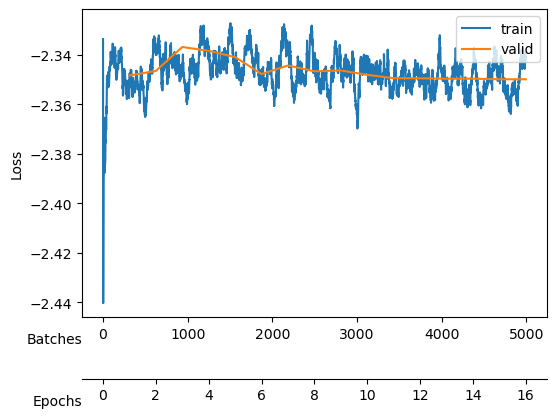
E=64+16*2; model_name = 'fbm' + f'_E{E}'
if not os.path.exists("./models/"+model_name+'.tar'):
save_model("./models/"+model_name, model, model_args, ds_args)Saved at ./models/fbm_E96.tarWe keep training to noise out the collapsed neurons while maintaining good reconstruction loss mix_gaussian_loss.
learn.loss_func.beta=1e-3; model_args.update(dict(beta=1e-3))learn.fit_one_cycle(16, lr_max=1e-3,)| epoch | train_loss | valid_loss | mix_gaussian_loss | kld | time |
|---|---|---|---|---|---|
| 0 | -2.348945 | -2.353240 | -2.364978 | 11.738488 | 01:10 |
| 1 | -2.358876 | -2.342992 | -2.353953 | 10.961354 | 01:10 |
| 2 | -2.350276 | -2.350280 | -2.360747 | 10.466887 | 01:11 |
| 3 | -2.341486 | -2.282615 | -2.292582 | 9.966481 | 01:11 |
| 4 | -2.342745 | -2.343670 | -2.353052 | 9.381420 | 01:10 |
| 5 | -2.345502 | -2.333569 | -2.343357 | 9.788860 | 01:10 |
| 6 | -2.361416 | -2.354589 | -2.363912 | 9.322714 | 01:10 |
| 7 | -2.350763 | -2.352047 | -2.361214 | 9.165956 | 01:11 |
| 8 | -2.354032 | -2.354136 | -2.363111 | 8.974744 | 01:10 |
| 9 | -2.351079 | -2.355446 | -2.364451 | 9.005571 | 01:10 |
| 10 | -2.348526 | -2.355358 | -2.364368 | 9.010308 | 01:10 |
| 11 | -2.349510 | -2.355702 | -2.364724 | 9.022109 | 01:10 |
| 12 | -2.359064 | -2.356081 | -2.365134 | 9.052643 | 01:10 |
| 13 | -2.358692 | -2.356183 | -2.365181 | 8.999000 | 01:10 |
| 14 | -2.357382 | -2.356289 | -2.365324 | 9.035031 | 01:10 |
| 15 | -2.347834 | -2.356310 | -2.365310 | 9.001582 | 01:11 |
E=64+16*3; model_name = 'fbm' + f'_E{E}'
if not os.path.exists("./models/"+model_name+'.tar'):
save_model("./models/"+model_name, model, model_args, ds_args)Saved at ./models/fbm_E112.tarlearn.loss_func.beta=2e-3; model_args.update(dict(beta=2e-3))learn.fit_one_cycle(16, lr_max=1e-3,)| epoch | train_loss | valid_loss | mix_gaussian_loss | kld | time |
|---|---|---|---|---|---|
| 0 | -2.350208 | -2.348301 | -2.362810 | 7.254685 | 01:10 |
| 1 | -2.337677 | -2.346455 | -2.359850 | 6.697080 | 01:11 |
| 2 | -2.345940 | -2.336791 | -2.349714 | 6.461686 | 01:11 |
| 3 | -2.339710 | -2.338348 | -2.351251 | 6.451570 | 01:10 |
| 4 | -2.344926 | -2.340880 | -2.353410 | 6.265362 | 01:11 |
| 5 | -2.349301 | -2.347707 | -2.359997 | 6.144722 | 01:11 |
| 6 | -2.336591 | -2.344263 | -2.356583 | 6.159823 | 01:10 |
| 7 | -2.345398 | -2.346607 | -2.358751 | 6.072074 | 01:10 |
| 8 | -2.342644 | -2.346272 | -2.358593 | 6.160376 | 01:10 |
| 9 | -2.345847 | -2.348051 | -2.360079 | 6.013485 | 01:11 |
| 10 | -2.351193 | -2.349379 | -2.361663 | 6.141795 | 01:10 |
| 11 | -2.350389 | -2.349450 | -2.361586 | 6.067914 | 01:10 |
| 12 | -2.351185 | -2.349608 | -2.361853 | 6.122767 | 01:10 |
| 13 | -2.344490 | -2.349607 | -2.361763 | 6.078405 | 01:10 |
| 14 | -2.347708 | -2.349838 | -2.362053 | 6.107482 | 01:11 |
| 15 | -2.342868 | -2.349836 | -2.362056 | 6.109914 | 01:10 |
E=64+16*4; model_name = 'fbm' + f'_E{E}'
if not os.path.exists("./models/"+model_name+'.tar'):
save_model("./models/"+model_name, model, model_args, ds_args)Saved at ./models/fbm_E128.tarlearn.loss_func.beta=4e-3; model_args.update(dict(beta=4e-3))learn.fit_one_cycle(16, lr_max=1e-3,)| epoch | train_loss | valid_loss | mix_gaussian_loss | kld | time |
|---|---|---|---|---|---|
| 0 | -2.344279 | -2.338168 | -2.358795 | 5.156413 | 01:10 |
| 1 | -2.345974 | -2.335615 | -2.355980 | 5.091214 | 01:14 |
| 2 | -2.328641 | -2.337625 | -2.357382 | 4.939382 | 01:11 |
| 3 | -2.320290 | -2.328844 | -2.348158 | 4.828393 | 01:11 |
| 4 | -2.326955 | -2.337008 | -2.356167 | 4.790024 | 01:11 |
| 5 | -2.326622 | -2.334390 | -2.353814 | 4.856228 | 01:10 |
| 6 | -2.328627 | -2.337150 | -2.356401 | 4.812714 | 01:11 |
| 7 | -2.324614 | -2.339001 | -2.358472 | 4.867772 | 01:11 |
| 8 | -2.321634 | -2.339200 | -2.358446 | 4.811536 | 01:10 |
| 9 | -2.346042 | -2.339435 | -2.358616 | 4.795233 | 01:10 |
| 10 | -2.342316 | -2.339132 | -2.358153 | 4.755326 | 01:11 |
| 11 | -2.333755 | -2.339544 | -2.358423 | 4.719747 | 01:10 |
| 12 | -2.331389 | -2.339730 | -2.358924 | 4.798558 | 01:10 |
| 13 | -2.339941 | -2.339780 | -2.358954 | 4.793717 | 01:11 |
| 14 | -2.335042 | -2.339912 | -2.359108 | 4.799071 | 01:11 |
| 15 | -2.337263 | -2.339907 | -2.359071 | 4.790753 | 01:10 |
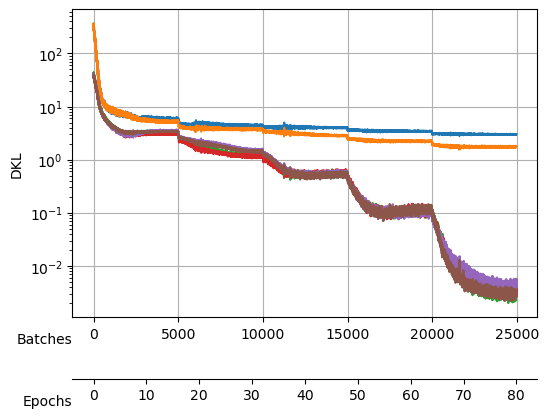
E=64+16*5; model_name = 'fbm' + f'_E{E}'
if not os.path.exists("./models/"+model_name+'.tar'):
save_model("./models/"+model_name, model, model_args, ds_args)Saved at ./models/fbm_E144.tarAfter training, we observe a good reconstruction loss around -2.36, while the \(D_{KL}\) is on the order of one for two neurons and the rest are three orders of magnitude below. We say that two neurons survive while the rest are noised out. We will see in the analysis tutorial how these two neurons encode the minimal relevant information to generate the trajectories.